Part I let’s talk a little bit about history …
For more than a hundred years, almost in parallel with the rise of corporations, business administration as an academic discipline offers ways to manage complexity in organizations. Although it has IT roots, Enterprise Architecture Management is one of the latest contributions to this field. I would like to have a short look at this history to give you an idea what happened in the past on the field of management of complexity and why that happened.

Organization Theory
Organization theory was the first and very early approach which splits up an Enterprise into functions, tasks, workers who execute tasks. It claimed that splitting up an enterprise can either be done by separation of different execution steps on the same task object or by distinction of task objects that are to be treated in each task. Procedural instructions and operating procedures defined the way how a single task or a set of tasks should be executed.
Cybernetics, System Theory
In the 1950s cybernetics and system theory appeared. The latter originally being defined on the field of biology found its way into many other disciplines. Both cybernetics as well as system theory influenced economics and information technology significantly. Enterprises started to be looked at as systems having interrelated components and serving a certain function.
Organization theory has dominated management of complexity in enterprises for decades (actually until the 1970s). Upcoming
economic challenges as well as the
emergence of computers were two main forces in that time which brought new methodologies into light from the 1980s on.
Business Process Engineering
Business Process Engineering aimed to increase efficiency and reduce time to market by introducing a new behavior centric definition of an organization and considering improvements information technology can bring. Processes (behavior) moved into foreground instead of isolated functions (structure).
IT Architecture
On the other hand, almost at the same time in the 1980s programmers started to think about managing complexity in software and IT systems by introducing a new discipline called “IT Architecture”. Some of those postulated software architecture considerations others introduced frameworks which aimed to systematically define the role of IT in an enterprise in terms of contributing economic value. All those initiatives were IT-centric though.
In organization theory’s terminology, enterprise IT systems are nothing more than a particular type of workers executing tasks. Hence, is obvious why IT systems found their way into new approaches to define an organization’s composition.
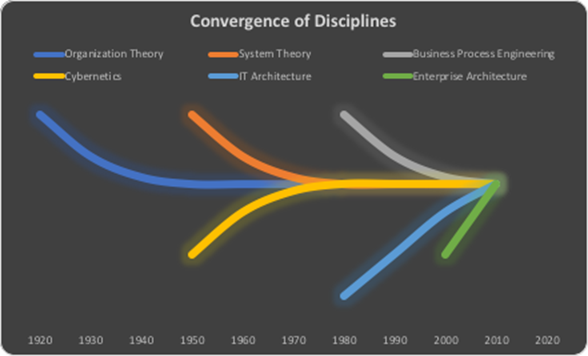
In the 1990s there were bunch of different business process modelling frameworks which allowed describing an enterprise from business as well as IT perspective. These were the beginnings of enterprise architecture management without naming it that way. But in the real world’s implementation it still it was an IT people’s playground. I remember times when we discussed with business how to optimize processes and derive requirements for it landscape transformation from those processes but they didn’t understand.
Enterprise Architecture Management
In the 2000s complexity increased in IT departments. Internet widely spread in the society and brought the net economy. New multi-tier architectures were established and open source were introduced for business purposes. Sustainability and stability of business as well as IT operations became very important.
Enterprise Architecture as a term was about to be established. Enterprise Architecture in that time integrated methods, models and techniques other management methods like organization theory, system theory, business process engineering and IT architecture had introduced before and added even some more. Enterprise architecture was about streamlining business functions, services and applications as well as technology and was meant to contribute value in order to achieve enterprise’s strategic goals.
If you look at how Gartner used to define Enterprise Architecture back in 2013 and how they changed their definition in 2017 you may recognize that there is a shift from ensuring sustainability and stability to enabling innovations and giving answers to distributions.
Gartner’s Definition 2013
“Enterprise architecture (EA) is the process of translating business vison and strategy into effective enterprise change by
creating communication and improving the key
requirements, principles and models that describe the
enterprise‘s future state and enable its evolution.”
Gartner’s Definition 2017
“Enterprise Architecture is a discipline for
proactively and holistically leading enterprise
responses to disruptive forces by identifying and analyzing the execution of change toward desired business vision and outcomes. EA
delivers value by presenting business and IT leaders with
signature-ready recommendations for adjusting policies and projects to achieve target business outcomes that capitalize on relevant business disruptions.”
So apparently “evolution” was not enough anymore. Is that actually a reaction on the impact mobile revolution and new digital disruptive business models started to have on the whole economy?
So what happened until then? Did Enterprise Architecture Management keep its promise according to the first definition in 2013? Is it going to be a proper answer to the latest challenges enterprises are facing according to the new definition?
In the next part of this series I will have a deeper look into why this shift of definition happened, what this has to do with agility and how this new approach has changed tools, methods and hopefully
mindset (which is the most important thing) behind Enterprise Architecture Management.


 If you look at how agile EAM is understood in other parts of the world and how big technology companies actually do EAM you might get a better understanding of how this topic has evolved and where this shift in Gartner’s definition comes from.
EAM derived from Disciplined Agile Delivery (DAD) is an interesting approach to have a deeper look at. It is amazing how pragmatic it is crafted and yet it does not seem to end up in chaos.
Principles for Performing Enterprise Architecture Agilely according to DAD are
If you look at how agile EAM is understood in other parts of the world and how big technology companies actually do EAM you might get a better understanding of how this topic has evolved and where this shift in Gartner’s definition comes from.
EAM derived from Disciplined Agile Delivery (DAD) is an interesting approach to have a deeper look at. It is amazing how pragmatic it is crafted and yet it does not seem to end up in chaos.
Principles for Performing Enterprise Architecture Agilely according to DAD are
 Gartner’s new definition of Enterprise Architecture Management is an implication of two main effects we have experienced in the last ten years.
Gartner’s new definition of Enterprise Architecture Management is an implication of two main effects we have experienced in the last ten years.

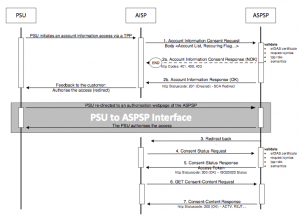 [Source: Berlin Group's Implementation Guidelines]
[Source: Berlin Group's Implementation Guidelines]
 This is exactly what people in that discussion pointed to. Existing platforms such as Amazon are for so many reasons in a far better position than banks in Germany in particular. And I absolutely agree with this. Banks need to open up their processes and services an integrate them into these existing platforms as one of the comments explains. Another questions which I am asking myself is what’s so new about this?
Back to the future …
I remember around 15 years ago there was already the call for banks to transform from a value chain to a value network. In Germany there have been a lot of papers under the name “Industrialization of Banking” about opening up product, sales and settlement of banking into three decoupled and separated main processes each of which can easily be recombined in value networks. In that concept one bank could develop products, the other one could offer them to the market and a third one could offer settlement of those products in a loosely coupled manner. That was the time when first banking fabrics for payment or securities processing came up.
If one takes the concept of value networks seriously than there is only one small step to an open banking idea where a bank can integrate its services into an existing platform such as amazon.
Why hasn’t that happened yet then? Is there some unfinished homework to be done?
If you can’t beat them join them
Indeed it could be too late for banks to become a platform themselves but it is not too late to integrate with existing platforms. If you can’t beat them join them.
On the other hand, as we know, existing platforms are becoming more and more powerful and network economics tend to create monopolies by their nature. This is being observed by competition authorities too. I hope they will not stand still and make soon sure that competition is upheld in this field.
This is exactly what people in that discussion pointed to. Existing platforms such as Amazon are for so many reasons in a far better position than banks in Germany in particular. And I absolutely agree with this. Banks need to open up their processes and services an integrate them into these existing platforms as one of the comments explains. Another questions which I am asking myself is what’s so new about this?
Back to the future …
I remember around 15 years ago there was already the call for banks to transform from a value chain to a value network. In Germany there have been a lot of papers under the name “Industrialization of Banking” about opening up product, sales and settlement of banking into three decoupled and separated main processes each of which can easily be recombined in value networks. In that concept one bank could develop products, the other one could offer them to the market and a third one could offer settlement of those products in a loosely coupled manner. That was the time when first banking fabrics for payment or securities processing came up.
If one takes the concept of value networks seriously than there is only one small step to an open banking idea where a bank can integrate its services into an existing platform such as amazon.
Why hasn’t that happened yet then? Is there some unfinished homework to be done?
If you can’t beat them join them
Indeed it could be too late for banks to become a platform themselves but it is not too late to integrate with existing platforms. If you can’t beat them join them.
On the other hand, as we know, existing platforms are becoming more and more powerful and network economics tend to create monopolies by their nature. This is being observed by competition authorities too. I hope they will not stand still and make soon sure that competition is upheld in this field. 
 October was heading to its end. We decided to meet for lunch once again. We agreed on a restaurant close to the river. You could sit outside at that place. It was a warm day when we met. One of those days at the autumn’s beginning where the sun still keeps alive hustle and bustle out there.
She was already waiting when I arrived. She sat at a table outside with a nice view over the river. There was a big fat camera on the table, close to that a book about big data and analytics.
“Hey!” I said, “What’s up? Sorry for being late!” I continued. “Hey!” she replied, “Don’t worry, all good!” she smiled. “What’s that for?” I pointed to the camera. ”Oh, Photography is one of my hobbies! It’s a good light today!” she explained, sounding like she’s bit proud of her camera.
October was heading to its end. We decided to meet for lunch once again. We agreed on a restaurant close to the river. You could sit outside at that place. It was a warm day when we met. One of those days at the autumn’s beginning where the sun still keeps alive hustle and bustle out there.
She was already waiting when I arrived. She sat at a table outside with a nice view over the river. There was a big fat camera on the table, close to that a book about big data and analytics.
“Hey!” I said, “What’s up? Sorry for being late!” I continued. “Hey!” she replied, “Don’t worry, all good!” she smiled. “What’s that for?” I pointed to the camera. ”Oh, Photography is one of my hobbies! It’s a good light today!” she explained, sounding like she’s bit proud of her camera.
 s and the amazing number of different open source initiatives for different purposes. That was what she has always been. A very skilled and open-minded computer scientist with no fear of change. She was going to start that job with a good general skillset in computer science and mathematics and no actual idea of big data. But with an open mindset and the will to learn. To learn fast.
This happened two and a half years ago.
Today she is her manager’s right-hand woman having a deep understanding of tools, technologies, what actually practically can be done and which pains one can expect in big data projects.
s and the amazing number of different open source initiatives for different purposes. That was what she has always been. A very skilled and open-minded computer scientist with no fear of change. She was going to start that job with a good general skillset in computer science and mathematics and no actual idea of big data. But with an open mindset and the will to learn. To learn fast.
This happened two and a half years ago.
Today she is her manager’s right-hand woman having a deep understanding of tools, technologies, what actually practically can be done and which pains one can expect in big data projects.
 Few days ago I talked with a friend of mine with which I used to work for a long time. We used to develop web applications with
Few days ago I talked with a friend of mine with which I used to work for a long time. We used to develop web applications with  Having a look at the strategic answers banks and insurers find around these questions one very quickly may perceive that pretty much all of them start modernizing their IT. They do this because the hope to achieve several goals at once. They all hope to increase efficiency and reduce costs. They either have missed to replace IT in the past twenty years and hence carry a lot of technical debts or even if they have done that once during that period they need to redo because of the speed of technological progress.
On the other hand they hope to create a set of new business areas where they might produce new sources of revenue. New IT may allow banks and insurers to expose parts of their business to the public so other companies might mash them up with other services and create new value propositions which in return will help banks and insurers to benefit from those kinds of network economics. Such kind of network effect for instance might appear by taking new FinTechs and InsurTechs into account. Those startups create new value propositions mostly for SME and retails business and they have a significant demand for foundation services they usually cannot provide themselves in first place.
Working together with startups in almost all cases means bringing up new services for SME and retail and this fits to the strategy. ING for instance mainly targets SME for creating new business. ING is going to spend up to 800 million Euros for continued digital transformation until 2021 implementing new lending platforms for SME and consumers.
Other banks and insurers are doing similiar things.
Indeed there are bunch of initiatives like ING’s. Banks and insurers are introducing new core systems. They will be exposing their services semipublicly soon. They will operate clouds where third party applications can run. We will see a bunch of announcements for new application marketplaces operated by insurers and banks where developers offer new cloud based apps using the exposed services and cloud operating models. They might also use existing marketplaces such as SAP’s HANA or Salesforce’s AppExchange.
I am very curious which one of those projects will succeed and which ones of those succeeded initiatives will actually survive.
The principles of network economics teach us the winner takes it all. Hence, not all of them can win.
And what I actually am asking myself is what if a developer decides to use services exposed by different banks and insurers in one single application simultaneously? Where does she publish the application? Does he publish and offer it on the marketplace of Bank A or Insurer B? On whose cloud will that application run when each bank or insurer offers its own cloud? How can hybric clouds or multi clouds establish solutions which really work?
Having a look at the strategic answers banks and insurers find around these questions one very quickly may perceive that pretty much all of them start modernizing their IT. They do this because the hope to achieve several goals at once. They all hope to increase efficiency and reduce costs. They either have missed to replace IT in the past twenty years and hence carry a lot of technical debts or even if they have done that once during that period they need to redo because of the speed of technological progress.
On the other hand they hope to create a set of new business areas where they might produce new sources of revenue. New IT may allow banks and insurers to expose parts of their business to the public so other companies might mash them up with other services and create new value propositions which in return will help banks and insurers to benefit from those kinds of network economics. Such kind of network effect for instance might appear by taking new FinTechs and InsurTechs into account. Those startups create new value propositions mostly for SME and retails business and they have a significant demand for foundation services they usually cannot provide themselves in first place.
Working together with startups in almost all cases means bringing up new services for SME and retail and this fits to the strategy. ING for instance mainly targets SME for creating new business. ING is going to spend up to 800 million Euros for continued digital transformation until 2021 implementing new lending platforms for SME and consumers.
Other banks and insurers are doing similiar things.
Indeed there are bunch of initiatives like ING’s. Banks and insurers are introducing new core systems. They will be exposing their services semipublicly soon. They will operate clouds where third party applications can run. We will see a bunch of announcements for new application marketplaces operated by insurers and banks where developers offer new cloud based apps using the exposed services and cloud operating models. They might also use existing marketplaces such as SAP’s HANA or Salesforce’s AppExchange.
I am very curious which one of those projects will succeed and which ones of those succeeded initiatives will actually survive.
The principles of network economics teach us the winner takes it all. Hence, not all of them can win.
And what I actually am asking myself is what if a developer decides to use services exposed by different banks and insurers in one single application simultaneously? Where does she publish the application? Does he publish and offer it on the marketplace of Bank A or Insurer B? On whose cloud will that application run when each bank or insurer offers its own cloud? How can hybric clouds or multi clouds establish solutions which really work?